党和国家高度重视出生缺陷防治能力建设,先后出台的《中共中央国务院关于优化生育政策促进人口长期均衡发展的决定》和《中国妇女发展纲要(2021-2030年)》、《中国儿童发展纲要(2021-2030年)》都要求进一步提升出生缺陷防治能力;国家卫生健康委也制定和发布了《出生缺陷防治能力提升计划(2023-2027年)》。无创产前DNA检测(NIPT)是出生缺陷防治中广泛运用的一类基础技术。该技术通过对孕妇(母体)外周血浆中游离的胎儿DNA片段进行捕获、测序和分析,能够较为精确的实现对常见染色体非整倍体患儿(21三体综合症/唐氏综合症、18三体综合症、13三体综合症等)的筛查。
然而,NIPT受限于胎儿DNA片段的长度和丰度,近年来NIPT技术在性能提升方面一直存在瓶颈。主要有三方面原因,一是目前使用的参考基因组来自国外,不能体现我国人群,特别是一个地区的人群特征,存在比对偏差,干扰检测精度;二是产科具有很强的地域/人群特点,但是大量的历史数据未能得到有效利用;三是传统NIPT技术只包括算法和操作流程,不具备从历史数据中习得有效信息并加以利用的模型结构和计算能力。
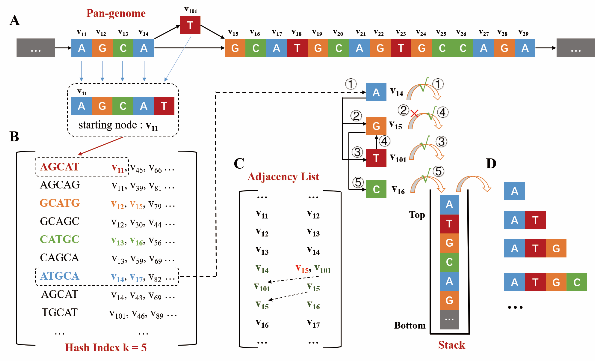
针对上述问题,西安交通大学计算机科学与技术学院生物信息管理与数字健康研究团队提出了一种用增量学习模型抽取历史数据中的人群特点,进而解决比对偏差的新型NIPT数据分析技术(NIPT-PG)。该技术设计了一种具有泛基因组图特征的数据结构和对应的学习算法,首次实现了基于大量人群的极低覆盖度检测数据构建地域人群的泛基因组图,从而获得能够指导比对校正的种群基因组多态性特征。在此基础上,以泛基因组图作为新型参考基因组,设计了一种考虑极短读段错配概率的序列-图比对算法,结合读段错配概率对阳性判断值进行校正,从而实现对非整倍体胎儿更早、更精准的筛查。
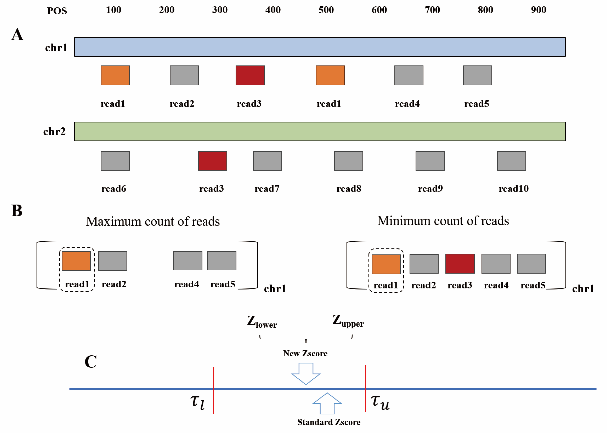
该技术是首次对生产用生物信息学方法进行的可学习性改造,提出了一种生产用生物信息学方法从流程到智能化的改造路径,在模型层面回答了怎么从历史数据中学习知识、学习的知识用什么数据结构存储两个关键问题,使该技术能够基于新数据不断学习和优化。研究团队与深圳华大基因研究院、武汉儿童医院/武汉市妇幼保健院合作,在数百例真实数据上验证了该技术的实用性。
近日,以上研究成果以《基于增量泛基因组方法:使无创产前检测技术能够从人群基因组中学习》(NIPT-PG: empowering non-invasive prenatal testing to learn from population genomics through an incremental pan-genomic approach)为题发表在生物信息学领域国际权威期刊《生物信息学简报》(Briefings in Bioinformatics)上。该期刊在数学与计算生物学大类(Mathematical & Computational Biology)的57个期刊中排名第1。西安交通大学计算机科学与技术学院薛正发博士为论文的第一作者,生物信息管理与数字健康研究团队王嘉寅教授、朱晓燕副教授,武汉儿童医院周爱芬教授、华大基因研究院金鑫研究团队共同参与研究工作。研究工作得到了国家自然科学基金重大项目等项目的支持。
论文链接:https://academic.oup.com/bib/article/25/4/bbae266/7688103

